使用BeautifulSoup进行定位提取的时候,因为数据是一个列表,所以会使用到索引,但是经常会提示索引越界
,这其实就是在我们匹配的时候,太过大意,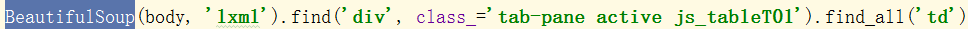
如上:
注意td和tr,tr说的是行,td是精确到元素的,所以后面的find_all很重要,td换成tr在执行后面的时候,匹配到的数据一定不一样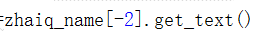
现在的索引是按照td标签的倒数第二个元素,如果换成tr那就是倒数第二行了
本文共 237 字,大约阅读时间需要 1 分钟。
使用BeautifulSoup进行定位提取的时候,因为数据是一个列表,所以会使用到索引,但是经常会提示索引越界
,这其实就是在我们匹配的时候,太过大意,
如上:
注意td和tr,tr说的是行,td是精确到元素的,所以后面的find_all很重要,td换成tr在执行后面的时候,匹配到的数据一定不一样
现在的索引是按照td标签的倒数第二个元素,如果换成tr那就是倒数第二行了
转载于:https://www.cnblogs.com/feifang/p/7118028.html